
The Cg Tutorial
The Cg Tutorial is now available, right here, online. You can purchase a beautifully printed version of this book, and others in the series, at a 30% discount courtesy of InformIT and Addison-Wesley.Please visit our Recent Documents page to see all the latest whitepapers and conference presentations that can help you with your projects.
Chapter 4. Transformations
When you write vertex or fragment programs, it is important to understand the coordinate systems that you are working with. This chapter explains the transformations that take place in the graphics pipeline, without going into detail about the underlying mathematics. The chapter has the following two sections:
- "Coordinate Systems" explains the various coordinate systems used to represent vertex positions as they are transformed prior to rasterization.
- "Applying the Theory" describes how to apply the theory of coordinate systems and matrices in Cg.
4.1 Coordinate Systems
The purpose of the graphics pipeline is to create images and display them on your screen. The graphics pipeline takes geometric data representing an object or scene (typically in three dimensions) and creates a two-dimensional image from it. Your application supplies the geometric data as a collection of vertices that form polygons, lines, and points. The resulting image typically represents what an observer or camera would see from a particular vantage point.
As the geometric data flows through the pipeline, the GPU's vertex processor transforms the constituent vertices into one or more different coordinate systems, each of which serves a particular purpose. Cg vertex programs provide a way for you to program these transformations yourself.
Vertex programs may perform other tasks, such as lighting (discussed in Chapter 5) and animation (discussed in Chapter 6), but transforming vertex positions is a task required by all vertex programs. You cannot write a vertex program that does not output a transformed position, because the rasterizer needs transformed positions in order to assemble primitives and generate fragments.
So far, the vertex program examples you've encountered limited their position processing to simple 2D transformations. This chapter explains how to implement conventional 3D transformations to render 3D objects.
Figure 4-1 illustrates the conventional arrangement of transforms used to process vertex positions. The diagram annotates the transitions between each transform with the coordinate space used for vertex positions as the positions pass from one transform to the next.
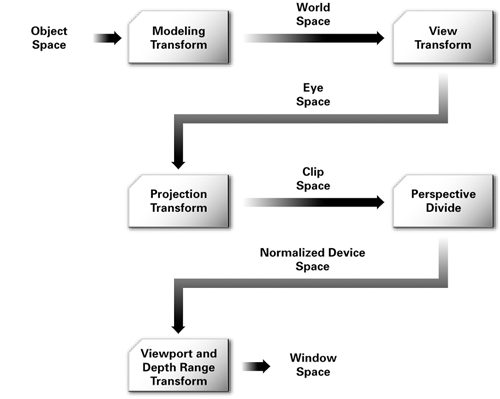
Figure 4-1 Coordinate Systems and Transforms for Vertex Processing
The following sections describe each coordinate system and transform in this sequence. We assume that you have some basic knowledge of matrices and transformations, and so we explain each stage of the pipeline with a high-level overview.
4.1.1 Object Space
Applications specify vertex positions in a coordinate system known as object space (also called model space). When an artist creates a 3D model of an object, the artist selects a convenient orientation, scale, and position with which to place the model's constituent vertices. The object space for one object may have no relationship to the object space of another object. For example, a cylinder may have an object-space coordinate system in which the origin lies at the center of the base and the z direction points along the axis of symmetry.
You represent each vertex position, whether in object space or in one of the subsequent spaces, as a vector. Typically, your application maintains each object-space 3D vertex position as an <x, y, z> vector. Each vertex may also have an accompanying object-space surface normal, also stored as an <x, y, z> vector.
4.1.2 Homogeneous Coordinates
More generally, we consider the <x, y, z> position vector to be merely a special case of the four-component <x, y, z, w> form. This type of four-component position vector is called a homogeneous position. When we express a vector position as an <x, y, z> quantity, we assume that there is an implicit 1 for its w component.
Mathematically, the w value is the value by which you would divide the x, y, and z components to obtain the conventional 3D (nonhomogeneous) position, as shown in Equation 4-1.
Equation 4-1 Converting Between Nonhomogeneous and Homogeneous Positions
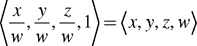
Expressing positions in this homogeneous form has many advantages. For one, multiple transformations, including projective transformations required for perspective 3D views, can be combined efficiently into a single 4x4 matrix. This technique is explained in Section 4.2. Also, using homogeneous positions makes it unnecessary to perform expensive intermediate divisions and to create special cases involving perspective views. Homogeneous positions are also handy for representing directions and curved surfaces described by rational polynomials.
We will return to the w component when discussing the projection transform.
4.1.3 World Space
Object space for a particular object gives it no spatial relationship with respect to other objects. The purpose of world space is to provide some absolute reference for all the objects in your scene. How a world-space coordinate system is established is arbitrary. For example, you may decide that the origin of world space is the center of your room. Objects in the room are then positioned relative to the center of the room and some notion of scale (Is a unit of distance a foot or a meter?) and some notion of orientation (Does the positive y-axis point "up"? Is north in the direction of the positive x-axis?).
4.1.4 The Modeling Transform
The way an object, specified in object space, is positioned within world space is by means of a modeling transform. For example, you may need to rotate, translate, and scale the 3D model of a chair so that the chair is placed properly within your room's world-space coordinate system. Two chairs in the same room may use the same 3D chair model but have different modeling transforms, so that each chair exists at a distinct location in the room.
You can mathematically represent all the transforms in this chapter as a 4x4 matrix. Using the properties of matrices, you can combine several translations, rotations, scales, and projections into a single 4x4 matrix by multiplying them together. When you concatenate matrices in this way, the combined matrix also represents the combination of the respective transforms. This turns out to be very powerful, as you will see.
If you multiply the 4x4 matrix representing the modeling transform by the object-space position in homogeneous form (assuming a 1 for the w component if there is no explicit w component), the result is the same position transformed into world space. This same matrix math principle applies to all subsequent transforms discussed in this chapter.
Figure 4-2 illustrates the effect of several different modeling transformations. The left side of the figure shows a robot modeled in a basic pose with no modeling transformations applied. The right side shows what happens to the robot after you apply a series of modeling transformations to its various body parts. For example, you must rotate and translate the right arm to position it as shown. Further transformations may be required to translate and rotate the newly posed robot into the proper position and orientation in world space.
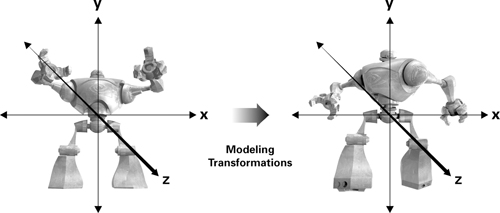
Figure 4-2 The Effect of Modeling Transformations
4.1.5 Eye Space
Ultimately, you want to look at your scene from a particular viewpoint (the "eye"). In the coordinate system known as eye space (or view space), the eye is located at the origin of the coordinate system. Following the standard convention, you orient the scene so the eye is looking down one direction of the z-axis. The "up" direction is typically the positive y direction.
Eye space, which is particularly useful for lighting, will be discussed in Chapter 5.
4.1.6 The View Transform
The transform that converts world-space positions to eye-space positions is the view transform. Once again, you express the view transform with a 4x4 matrix.
The typical view transform combines a translation that moves the eye position in world space to the origin of eye space and then rotates the eye appropriately. By doing this, the view transform defines the position and orientation of the viewpoint.
Figure 4-3 illustrates the view transform. The left side of the figure shows the robot from Figure 4-2 along with the eye, which is positioned at <0, 0, 5> in the world-space coordinate system. The right side shows them in eye space. Observe that eye space positions the origin at the eye. In this example, the view transform translates the robot in order to move it to the correct position in eye space. After the translation, the robot ends up at <0, 0, -5> in eye space, while the eye is at the origin. In this example, eye space and world space share the positive y-axis as their "up" direction and the translation is purely in the z direction. Otherwise, a rotation might be required as well as a translation.
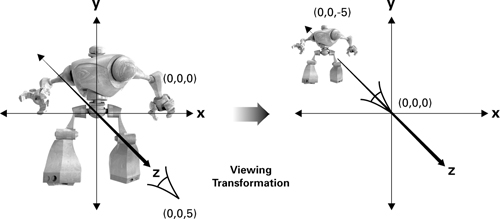
Figure 4-3 The Effect of the Viewing Transformation
The Modelview Matrix
Most lighting and other shading computations involve quantities such as positions and surface normals. In general, these computations tend to be more efficient when performed in either eye space or object space. World space is useful in your application for establishing the overall spatial relationships between objects in a scene, but it is not particularly efficient for lighting and other shading computations.
For this reason, we typically combine the two matrices that represent the modeling and view transforms into a single matrix known as the modelview matrix. You can combine the two matrices by simply multiplying the view matrix by the modeling matrix.
4.1.7 Clip Space
Once positions are in eye space, the next step is to determine what positions are actually viewable in the image you eventually intend to render. The coordinate system subsequent to eye space is known as clip space, and coordinates in this space are called clip coordinates.
The vertex position that a Cg vertex program outputs is in clip space. Every vertex program optionally outputs parameters such as texture coordinates and colors, but a vertex program always outputs a clip-space position. As you have seen in earlier examples, the POSITION semantic is used to indicate that a particular vertex program output is the clip-space position.
4.1.8 The Projection Transform
The transform that converts eye-space coordinates into clip-space coordinates is known as the projection transform.
The projection transform defines a view frustum that represents the region of eye space where objects are viewable. Only polygons, lines, and points that are within the view frustum are potentially viewable when rasterized into an image. OpenGL and Direct3D have slightly different rules for clip space. In OpenGL, everything that is viewable must be within an axis-aligned cube such that the x, y, and z components of its clip-space position are less than or equal to its corresponding w component. This implies that -w 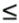 x w, -w y w, and -w z w. Direct3D has the same clipping requirement for x and y, but the z requirement is 0 z w. These clipping rules assume that the clip-space position is in homogeneous form, because they rely on w.
x w, -w y w, and -w z w. Direct3D has the same clipping requirement for x and y, but the z requirement is 0 z w. These clipping rules assume that the clip-space position is in homogeneous form, because they rely on w.
The projection transform provides the mapping to this clip-space axis-aligned cube containing the viewable region of clip space from the viewable region of eye space—otherwise known as the view frustum. You can express this mapping as a 4x4 matrix.
The Projection Matrix
The 4x4 matrix that corresponds to the projection transform is known as the projection matrix.
Figure 4-4 illustrates how the projection matrix transforms the robot in eye space from Figure 4-3 into clip space. The entire robot fits into clip space, so the resulting image should picture the robot without any portion of the robot being clipped.
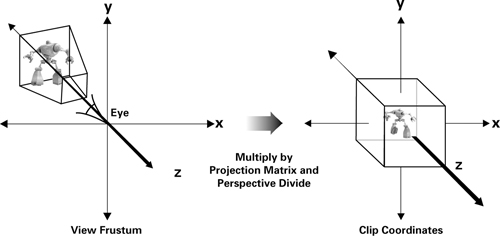
Figure 4-4 The Effect of the Projection Matrix
The clip-space rules are different for OpenGL and Direct3D and are built into the projection matrix for each respective API. As a result, if Cg programmers rely on the appropriate projection matrix for their choice of 3D programming interface, the distinction between the two clip-space definitions is not apparent. Typically, the application is responsible for providing the appropriate projection matrix to Cg programs.
4.1.9 Normalized Device Coordinates
Clip coordinates are in the homogenous form of <x, y, z, w>, but we need to compute a 2D position (an x and y pair) along with a depth value. (The depth value is for depth buffering, a hardware-accelerated way to render visible surfaces.)
Perspective Division
Dividing x, y, and z by w accomplishes this. The resulting coordinates are called normalized device coordinates. Now all the visible geometric data lies in a cube with positions between <-1, -1, -1> and <1, 1, 1> in OpenGL, and between <-1, -1, 0> and <1, 1, 1> in Direct3D.
The 2D vertex programs in Chapters 2 and 3 output what you now know as normalized device coordinates. The 2D output position in these examples assumed an implicit z value of 0 and a w value of 1.
4.1.10 Window Coordinates
The final step is to take each vertex's normalized device coordinates and convert them into a final coordinate system that is measured in pixels for x and y. This step, called the viewport transform, feeds the GPU's rasterizer. The rasterizer then forms points, lines, or polygons from the vertices, and generates fragments that determine the final image. Another transform, called the depth range transform, scales the z value of the vertices into the range of the depth buffer for use in depth buffering.
4.2 Applying the Theory
Despite all the discussion about coordinate spaces, the Cg code you need for transforming vertices correctly is quite trivial. Normally, the vertex program receives vertex positions in object space. The program then multiplies each vertex by the modelview and projection matrices to get that vertex into clip space. In practice, you would concatenate these two matrices so that just one multiplication is needed instead of two. Figure 4-5 illustrates this principle by showing two ways to get from object coordinates to clip coordinates.
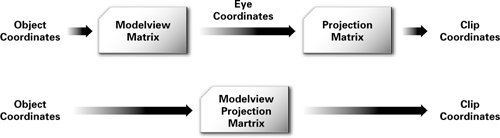
Figure 4-5 Optimizations for Transforming to Clip Space
Example 4-1 shows how a typical Cg program would efficiently handle 3D vertex transformations from object space directly to clip space.
Example 4-1. The C4E1v_transform Vertex Program
void C4E1v_transform(float4 position : POSITION,
out float4 oPosition : POSITION,
uniform float4x4 modelViewProj)
{
// Transform position from object space to clip space
oPosition = mul(modelViewProj, position);
}
The program takes the object-space position ( position ) and concatenated modelview and projection matrices ( modelViewProj ) as input parameters. Your OpenGL or Direct3D application would be responsible for providing this data. There are Cg runtime routines that help you load the appropriate matrix based on the current OpenGL or Direct3D transformation state. The position parameter is then transformed with a matrix multiplication, and the result is written out to oPosition :
// Transform position from object space to clip space oPosition = mul(modelViewProj, position);
In this book, we explicitly assign all output parameters, even if they are simply being passed through. We use the " o " prefix to differentiate input and output parameters that have the same names.
4.3 Exercises
-
Answer this: List the various coordinate spaces and the sequence of transformations used to move from one to the next.
-
Answer this: If you are interested in the theory of transformations, list some situations where you can use just a 3x3 matrix for the modelview and projection matrices instead of a complete 4x4 matrix.
-
Try this yourself: Use cgc to output the vertex program assembly for the C4E1v_transform example. The DP4 instruction computes a four-component dot product. How many such instructions are generated by the program's mul routine?
4.4 Further Reading
Computer graphics textbooks explain vertex transformation and develop more of the matrix math underlying the topic than presented here. We recommend Edward Angel's Interactive Computer Graphics: A Top-Down Approach with OpenGL, Third Edition (Addison-Wesley, 2002).
If you want to develop your intuition for the projective transformations that underlie vertex transformation and be entertained at the same time, read Jim Blinn's Corner: A Trip Down the Graphics Pipeline (Morgan Kaufmann, 1996).
Graphics Gems (Academic Press, 1994), edited by Andrew Glassner, has many useful short articles about modeling, transformation, and matrix techniques.
Copyright
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals.
The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein.
The publisher offers discounts on this book when ordered in quantity for bulk purchases and special sales. For more information, please contact:
U.S. Corporate and Government Sales
(800) 382-3419
corpsales@pearsontechgroup.com
For sales outside of the U.S., please contact:
International Sales
international@pearsontechgroup.com
Visit Addison-Wesley on the Web: www.awprofessional.com
Library of Congress Control Number: 2002117794
Copyright © 2003 by NVIDIA Corporation
Cover image © 2003 by NVIDIA Corporation
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form, or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior consent of the publisher. Printed in the United States of America. Published simultaneously in Canada.
For information on obtaining permission for use of material from this work, please submit a written request to:
Pearson Education, Inc.
Rights and Contracts Department
75 Arlington Street, Suite 300
Boston, MA 02116
Fax: (617) 848-7047
Text printed on recycled paper at RR Donnelley Crawfordsville in Crawfordsville, Indiana.
8 9 10111213 DOC 09 08 07
8th Printing, November 2007
Developer News Homepage

Developer Login
Become a
Registered Developer
Developer Tools
Documentation
DirectX
OpenGL
GPU Computing
Handheld
Events Calendar
Newsletter Sign-Up
Drivers
Jobs (1)
Contact
Legal Information
Site Feedback
- Copyright, Dedications and Foreword
- Chapter 1. Introduction
- Chapter 2. The Simplest Programs
- Chapter 3. Parameters, Textures, and Expressions
- Chapter 4. Transformations
- Chapter 5. Lighting
- Chapter 6. Animation
- Chapter 7. Environment Mapping Techniques
- Chapter 8. Bump Mapping
- Chapter 9. Advanced Topics
- Chapter 10. Profiles and Performance
- Appendix A. Getting Started with Cg
- Appendix B. The Cg Runtime
- Appendix C. The CgFX File Format
- Appendix D. Cg Keywords
- Appendix E. Cg Standard Library Functions
- Color Plates